超简单!低配电脑,本地部署DeepSeek R1!开源免费 | 纯CPU | 新手友好
DeepSeek R1介绍
要说春节这几天,AI圈最火的,就属deepseek推出的R1模型了。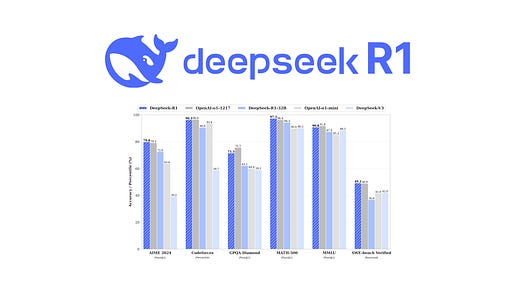
就在前几天,英伟达官网宣布:
DeepSeek R1模型,已作为英伟达 NIM微服务预览版,在它的开发者平台上线,双方开始了技术合作。
Meta的创始人,扎克伯格也表示,DeepSeek在基础设施优化方面,取得了”新颖的进展”。并指出这些创新,已经公开发表,Meta可以通过学习相关方法,从中受益。
那么deepseek R1模型,到底有哪些亮眼的地方,能够受到业界的广泛关注呢?
根据deepseek官网的介绍,deepseek R1模型,在后训练阶段,大规模使用了强化学习技术。在仅有极少标注数据的情况下,能够极大提升模型的推理能力。在数学、代码、自然语言推理等任务上,性能可以比肩 OpenAI o1 模型正式版。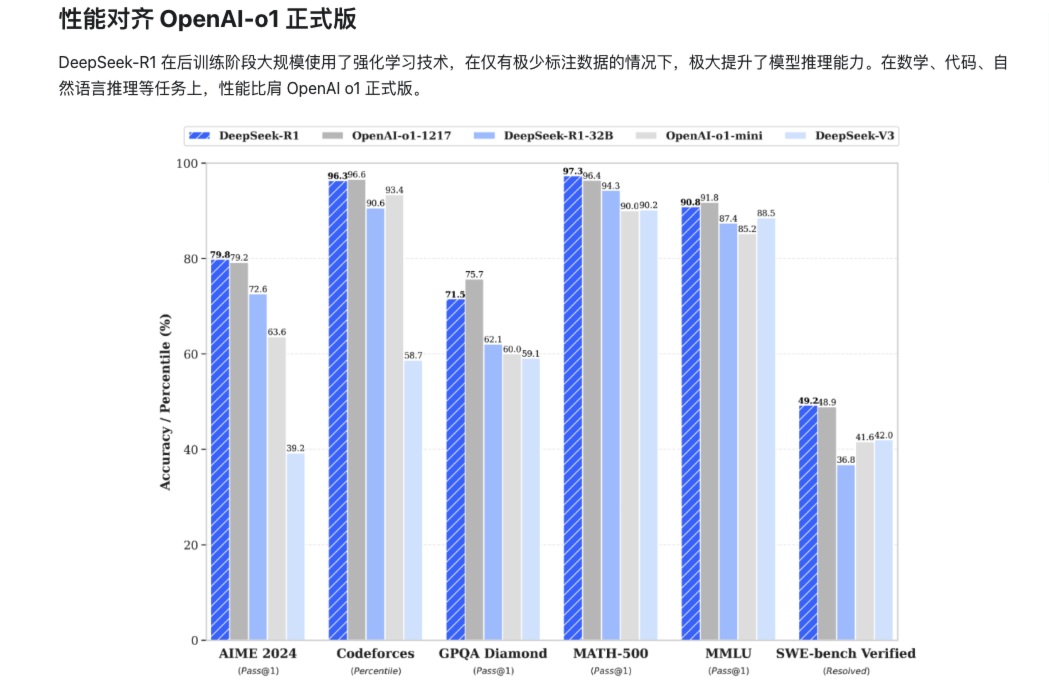
而且最重要的是,它的训练成本非常低,整个训练过程。只使用了2048块,符合美国出口管制版本的,英伟达H800 GPU,训练时长55天,成本约557万美元。是同类模型成本的 1/20,推理成本更是只有 OpenAI 模型的 1/30。而且和OpenAI不同,deepseek的模型都是开源的。(虽然叫OpenAI但是一点都不Open)
deepseek R1模型,推出后不到一周,股票市场出现巨大波动。英伟达股票,在1月27日暴跌近17%,市值减少约5900亿美元。这主要是因为,投资者担心deepseek R1的出现,可能会引发AI模型的低成本浪潮。如果是这样,那以后训练大模型,就不再需要太多的高端GPU了,那这势必会影响,英伟达这些公司的发展。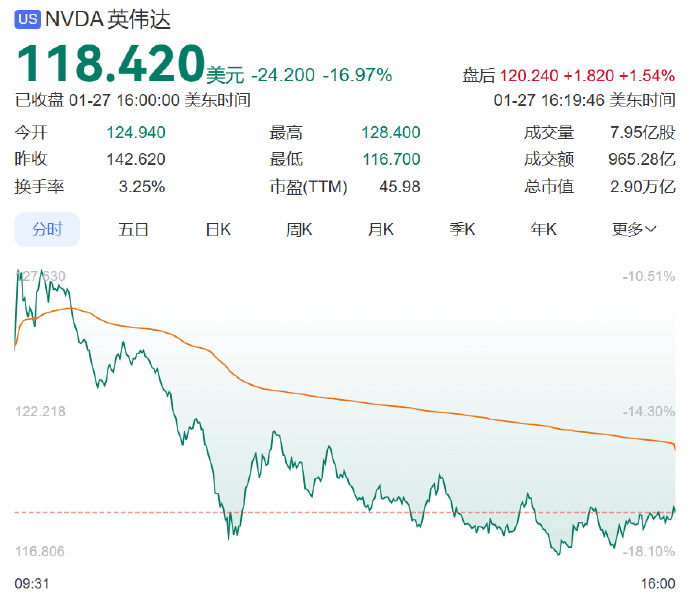
DeepSeek R1本地部署
如果想要使用 deepseek R1模型,除了web对话和API,你还可以在本地,自己部署一个蒸馏版的模型。这样使用起来很方便,而且不受线上服务的影响。下面我们就来介绍,如何在本地部署deepseek R1模型。
本地部署
首先我们需要安装一个,模型管理工具,用来运行和管理本地部署的模型。这里我们选择使用 ollama,它是由Meta研发的,一个开源大模型管理工具。打开ollama的官网,然后点击下载,根据自己的系统下载对应的安装包。
下载完以后,安装 ollama 。点击next,然后安装命令行,这样我们就可以在命令行中,和AI进行对话了。然后点击完成,使用ollama run llama3.2这条命令,可以安装llama3.2模型。这里我们先不安装它,直接去安装deepseek R1模型。打开安装好的 ollama,然后在命令行输入 ollama list,可以查看已经安装的模型。可以看到,我们现在还没有安装模型。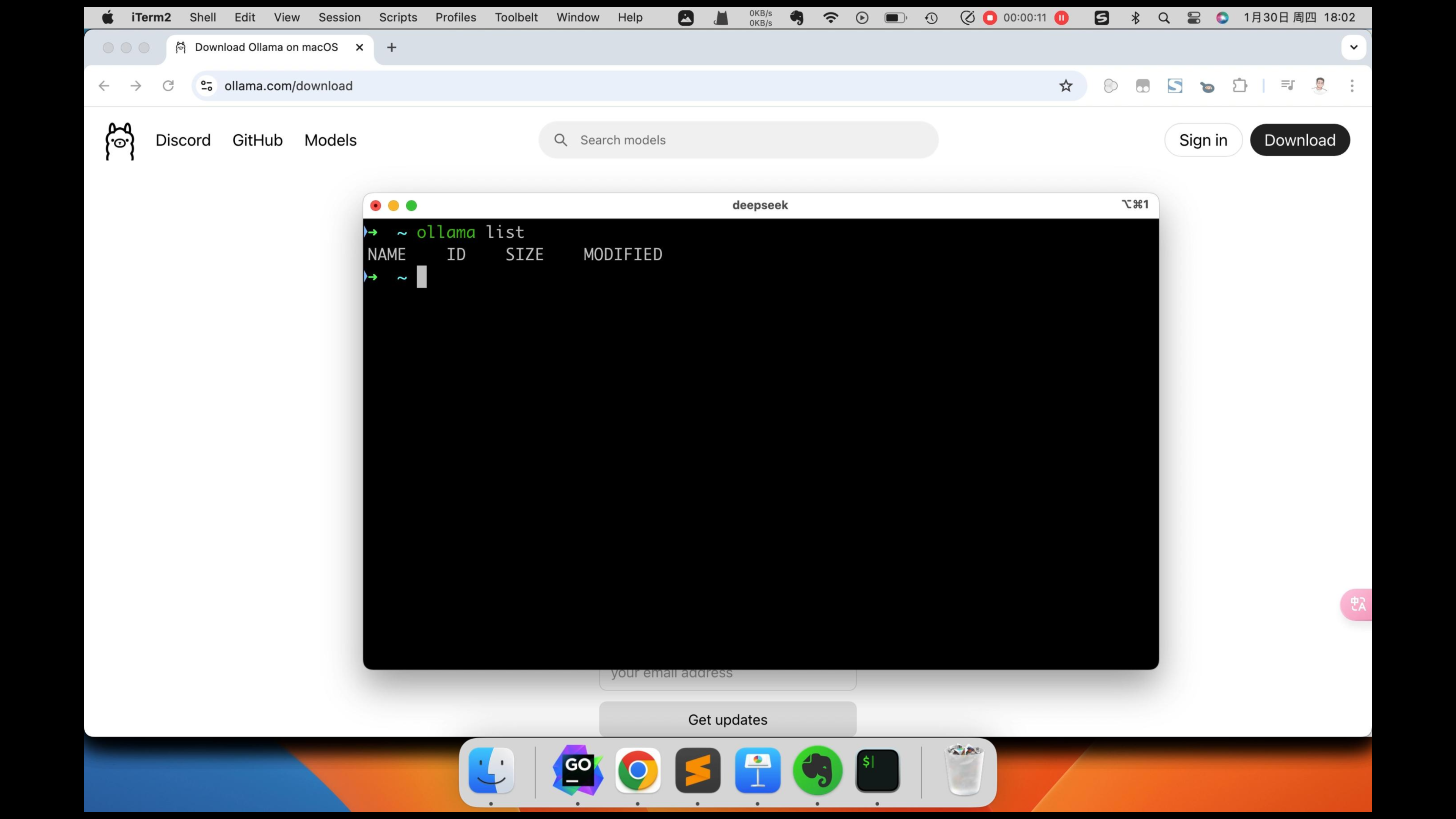
接下来,我们来安装deepseek R1模型。在ollama 的官网,点击 models,可以看到,第一个就是deepseek R1模型。点击打开它,在这里可以根据参数量级,来选择模型,最低的是1.5b,最高671b。这里的1.5b到70b这6个模型,并不是满血的 deepseek R1模型。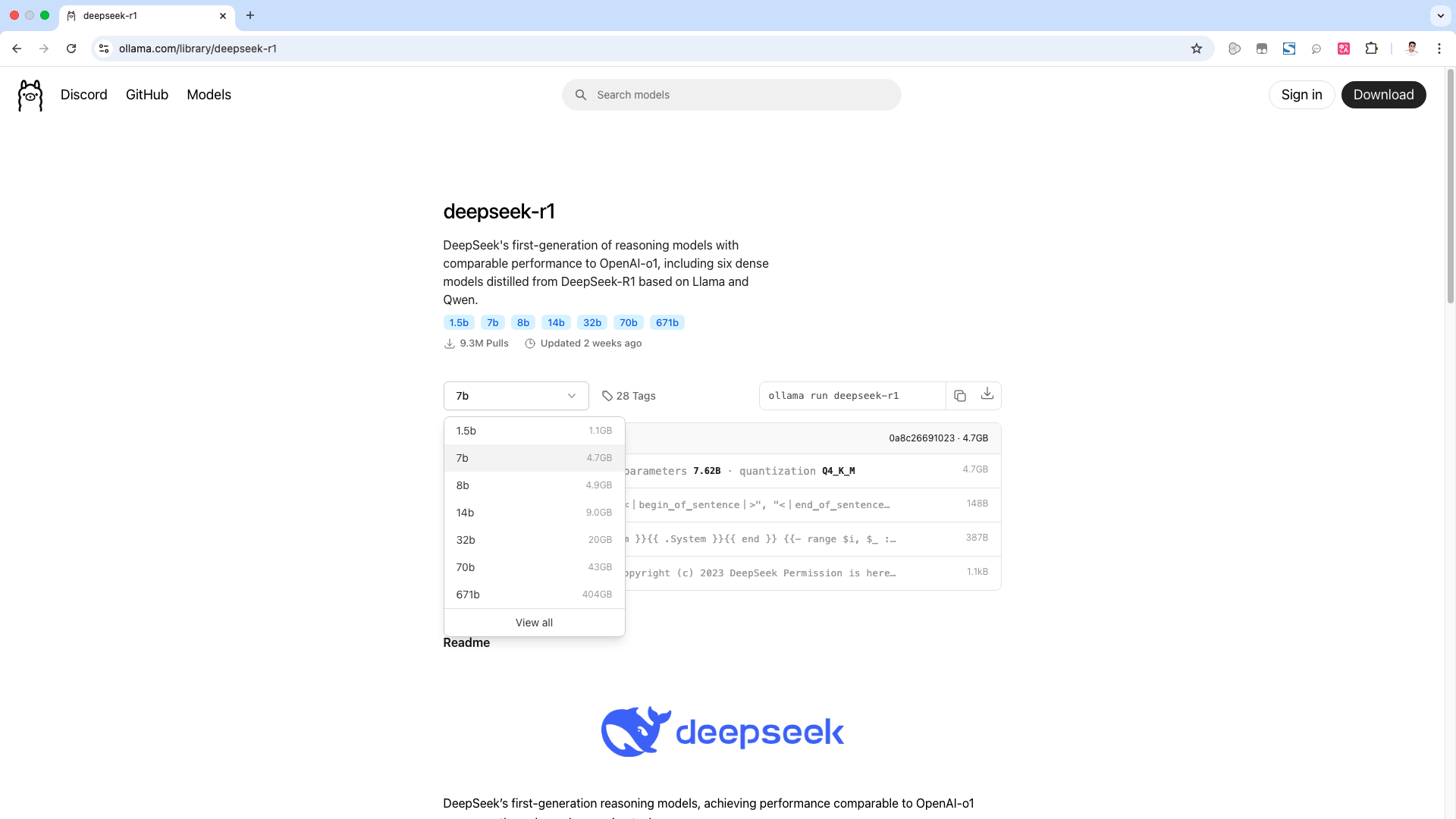
而是deepseek R1的蒸馏模型,所谓蒸馏模型,简单来说就是。deepseek R1模型把知识,传授给一个小模型。那这个小模型就是, deepseek R1 的一个蒸馏模型。这样可以降低模型的复杂度和计算量,从而提高模型的运行效率。而1.5b、7b、8b这些参数量级,可以理解为,小模型从deepseek R1,学习到的知识量。参数越多,代表学习到的知识越多,推理能力也就越强。
比如这个7b的蒸馏模型,就是以千问模型为基底的,一个蒸馏模型。而我们要部署的,就是这些蒸馏版的模型。因为满血的 deepseek R1模型,大小有几百个G,需要超过336G的显存才能运行起来。普通的家用电脑,纯CPU的话是,完全跑不动的,但是我们可以根据,自己的机器配置。选择合适的蒸馏模型来部署,我这里使用的设备,是一台老的MacBook Pro。
CPU配置为4核2G,内存为16G,我这里选择使用这个,7b的蒸馏模型来部署。如果不知道自己的机器,适合部署哪个模型,可以参考这个表格。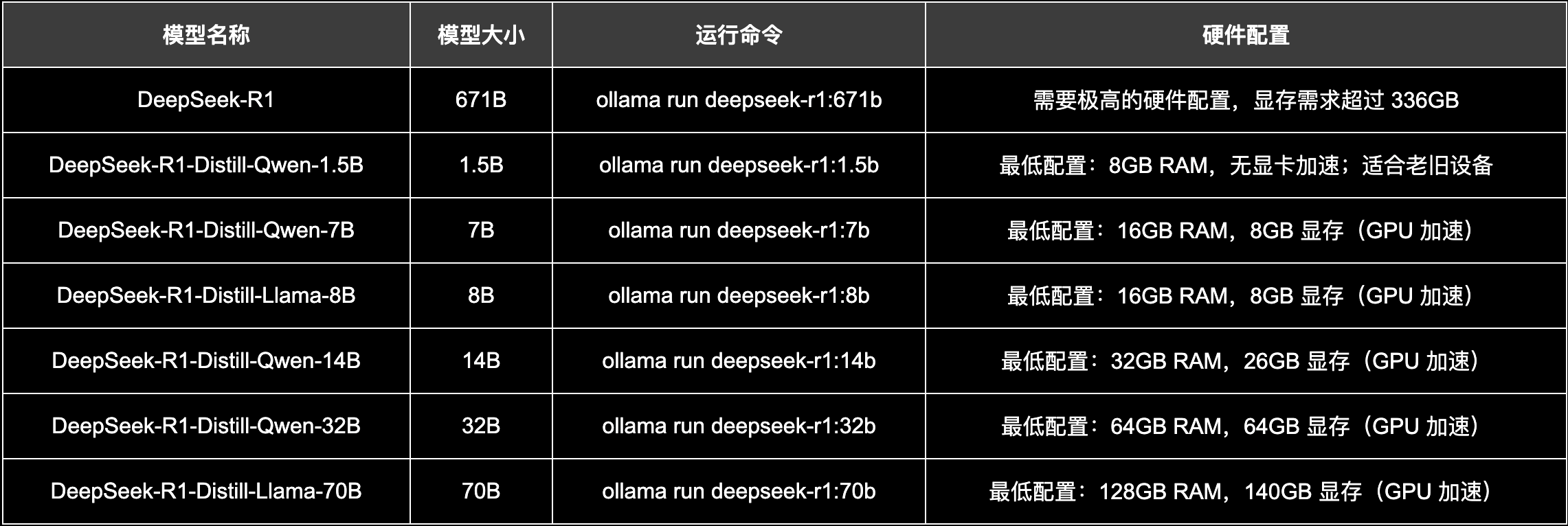
我们复制ollama run deepseek-r1:7b这条命令,然后以root权限执行它。这里需要输入我们的root密码。这样它就开始下载模型,并进行安装了。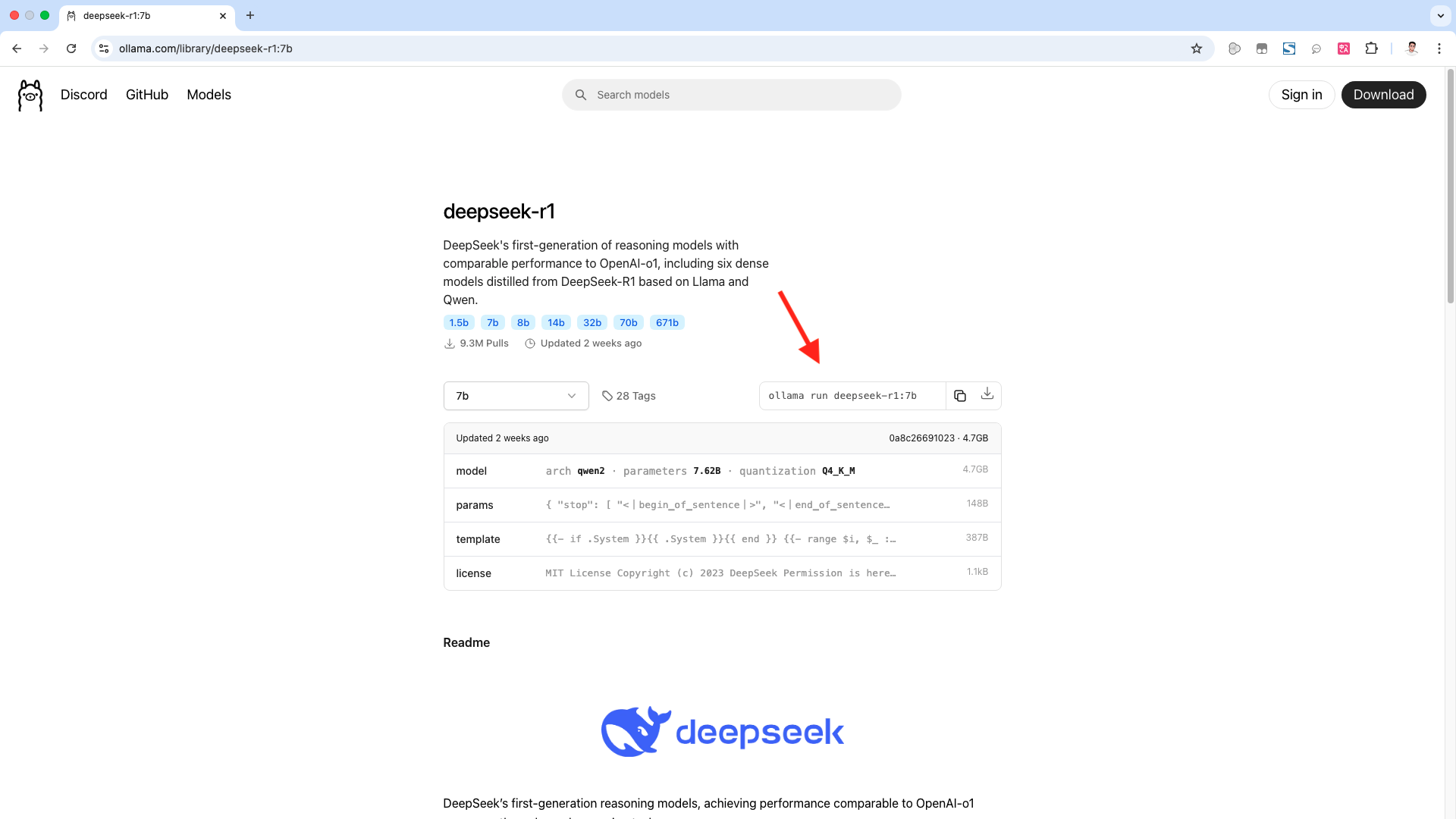
安装完成了,可以看到我们现在已经进入到, deepseek R1模型的对话页面了。现在,在命令行,就可以和模型对话了,我们来试一下。可以看到,使用没有问题。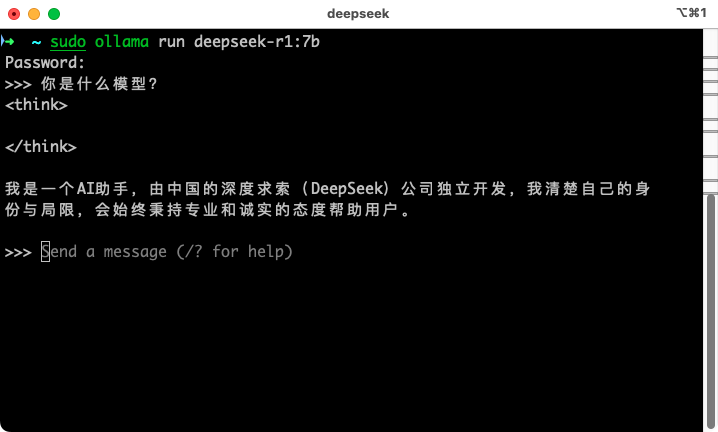
但是使用命令行的方式,很不方便,我们下面来看一下。如何和 ChatGPT 一样,在web页面和AI模型对话。首先我们需要安装这个 page assist 浏览器插件。
然后打开插件,在模型这里,选择我们安装的, deepseek R1 7b模型。然后就可以和ChatGPT一样,在网页中,和deepseek R1模型对话了。下面我们让他实现一个登录页面,来看一下效果怎么样。可以看到处理速度还是比较慢的,而且我这这个设备的CPU,都已经跑的飞起来了。也就勉强能够运行这个7b的模型。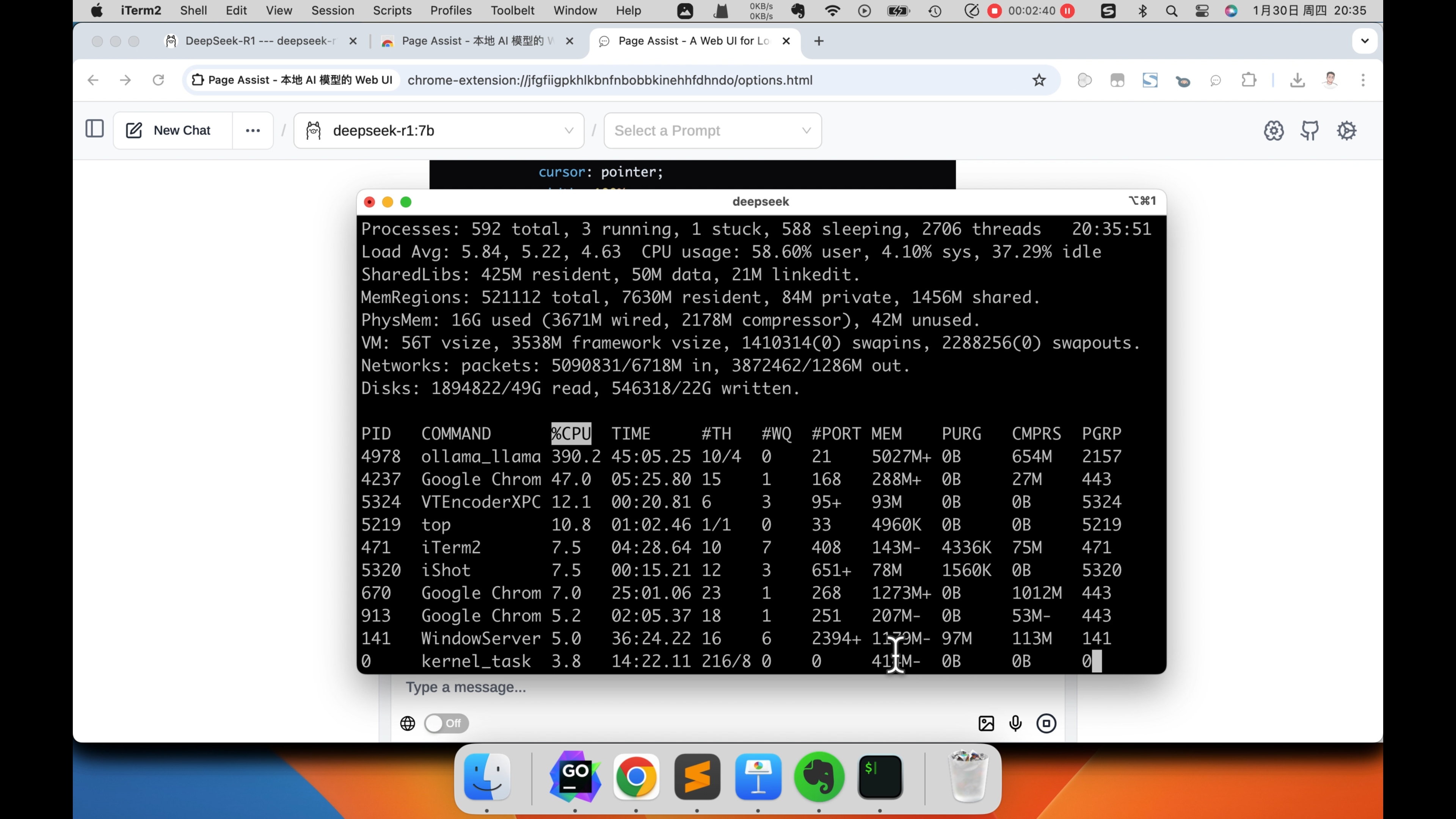
代码生成完了,我们下载下来,在浏览器打开看一下。可以看到效果还是可以的,那这个7b的蒸馏模型。它的推理能力还是比较弱的,适合用来处理一些简单的任务。比如AI对话,文案编辑等等。如果需要更强的推理能力,可以部署参数量更大的蒸馏模型。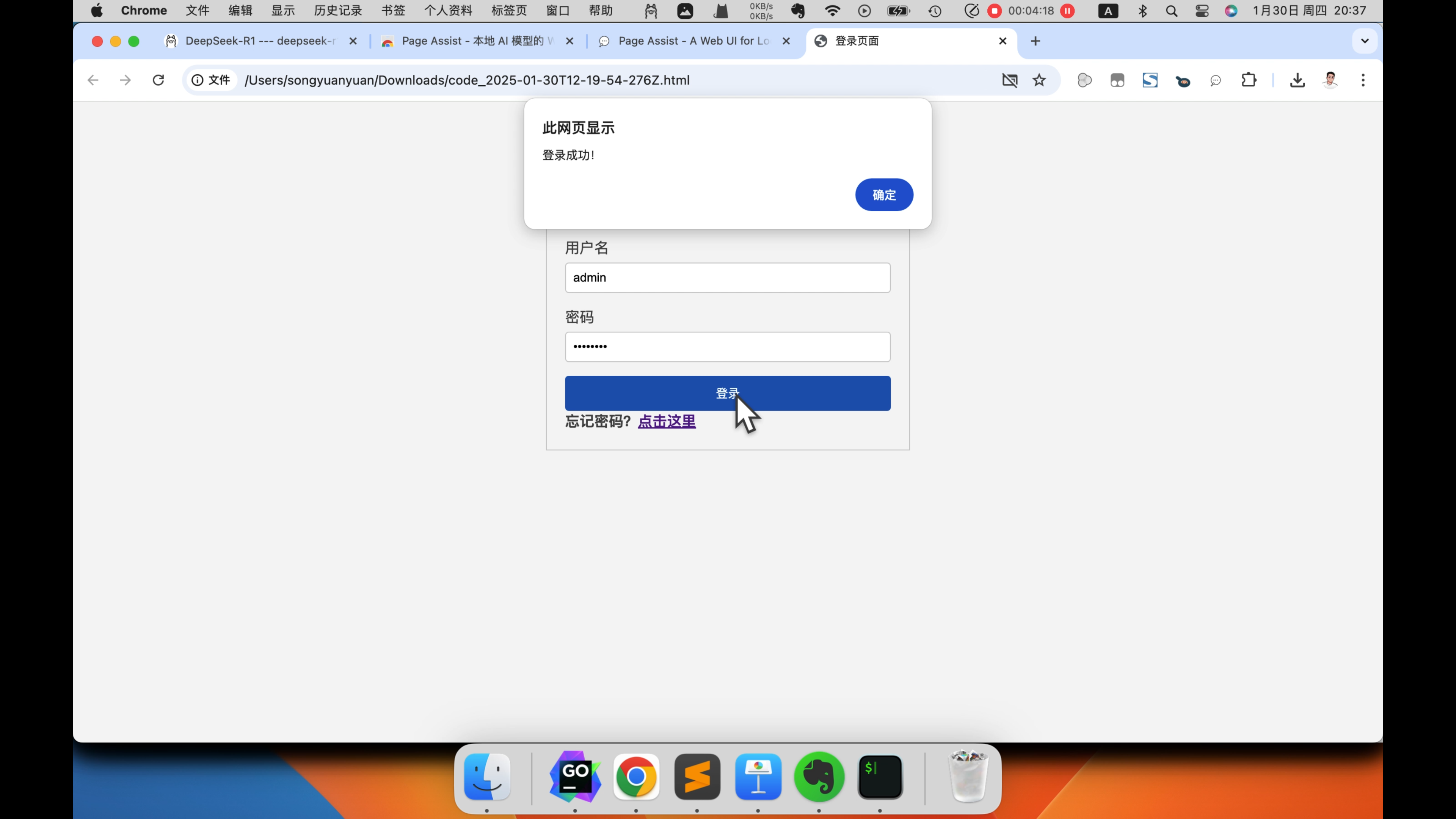
搭配vscode
最后我们再来看一下,如何把本地部署的这个 deepseek R1 7b模型。加入到vscode中,用来进行代码开发。这里我们介绍2个,常用的AI编程插件,continue和cline。
1. continue插件
先来看continue插件,点击上面的:添加一个模型。provider这里选择 ollama,然后下面的models选择 deepseek coder。点击connect,然后需要修改,这个配置文件中的 model的值。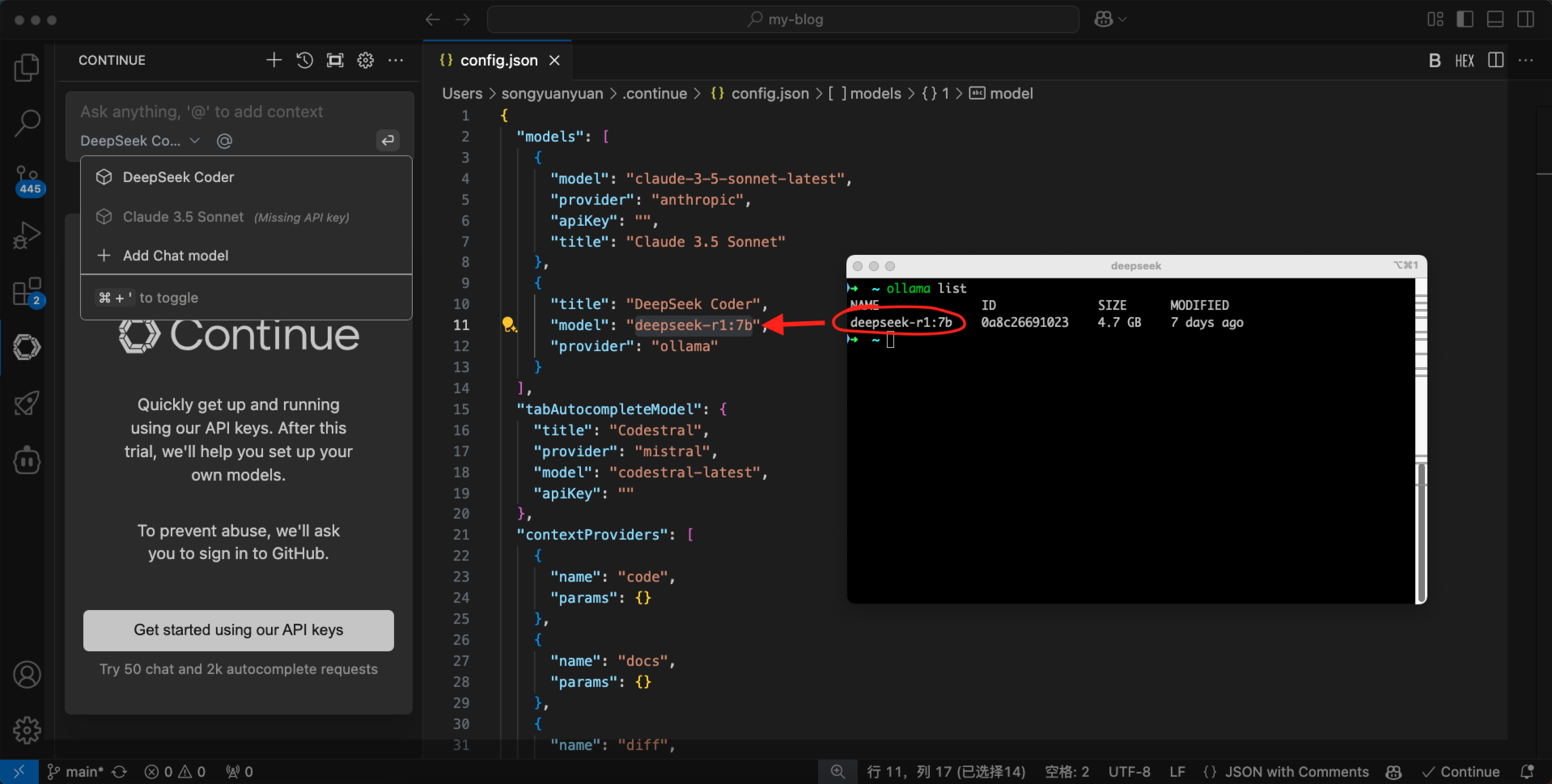
这个model的值,我们需要从 ollama 来获取,执行 ollama list 命令。然后复制这个 deepseek R1 7b模型的name,回到配置文件。把复制的模型name粘贴进去,然后保存配置文件就可以了。来试一下效果。可以看到,现在continue插件,已经可以使用deepseek R1 7b模型了。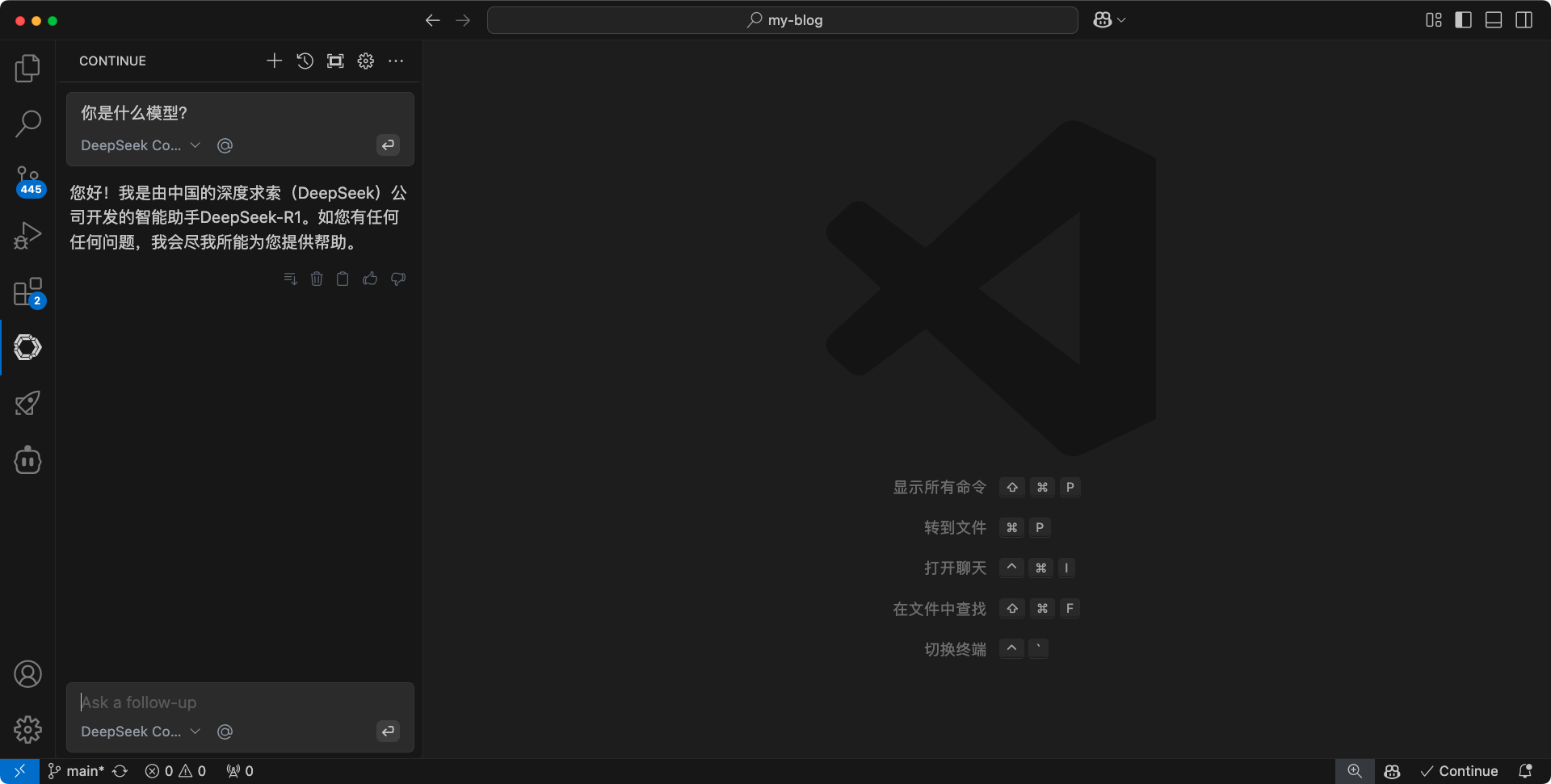
2. cline插件
接下来,再来配置 cline 插件。点击插件右上角的设置,api provider这里选择 ollama。然后下面的model ID这里,粘贴上我们上一步,使用ollama list获取到的,模型的name。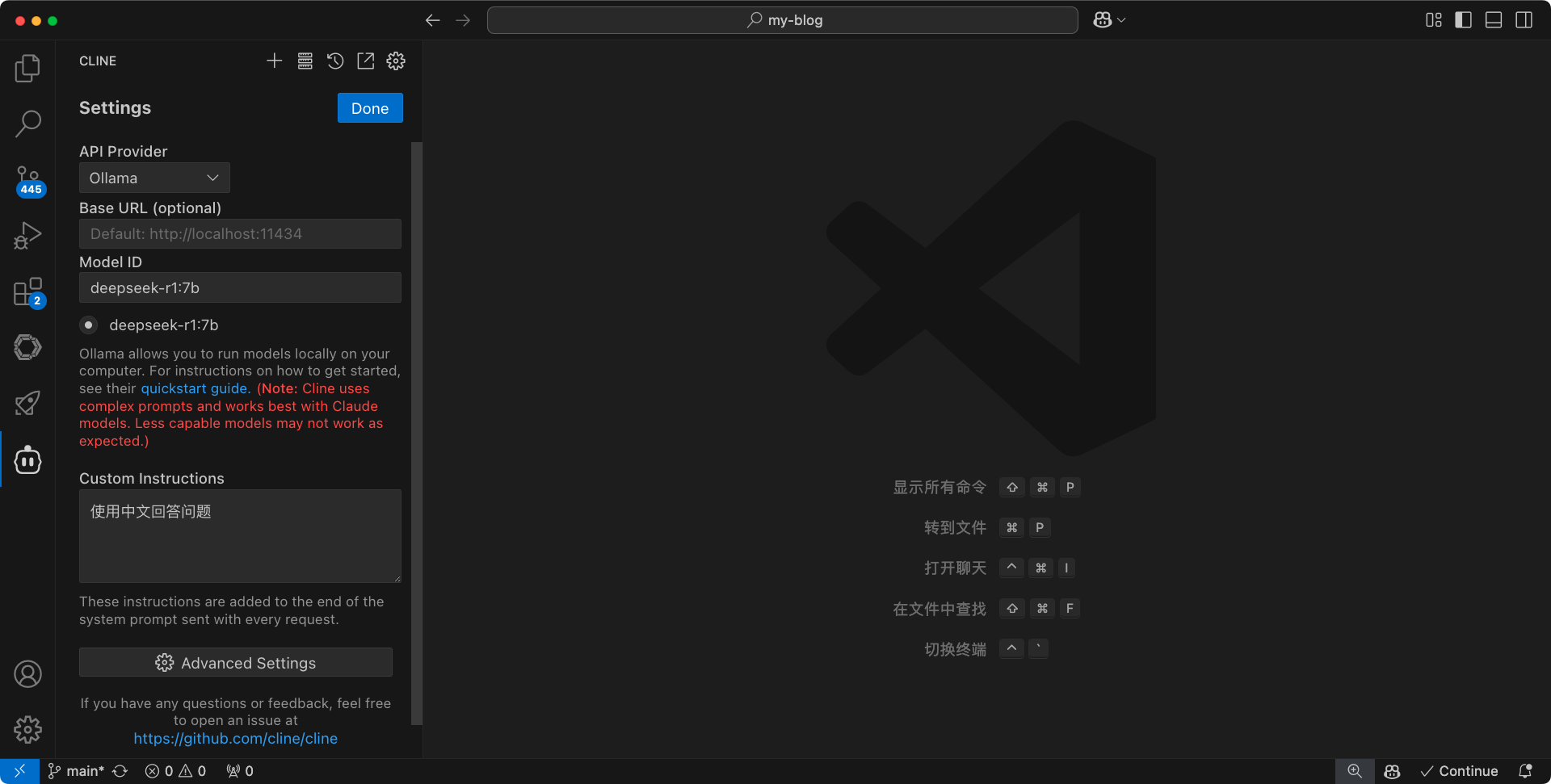
来测试下效果,可以看到,这里一直卡在API request这一步。不止cline插件,roo code 插件也是一样。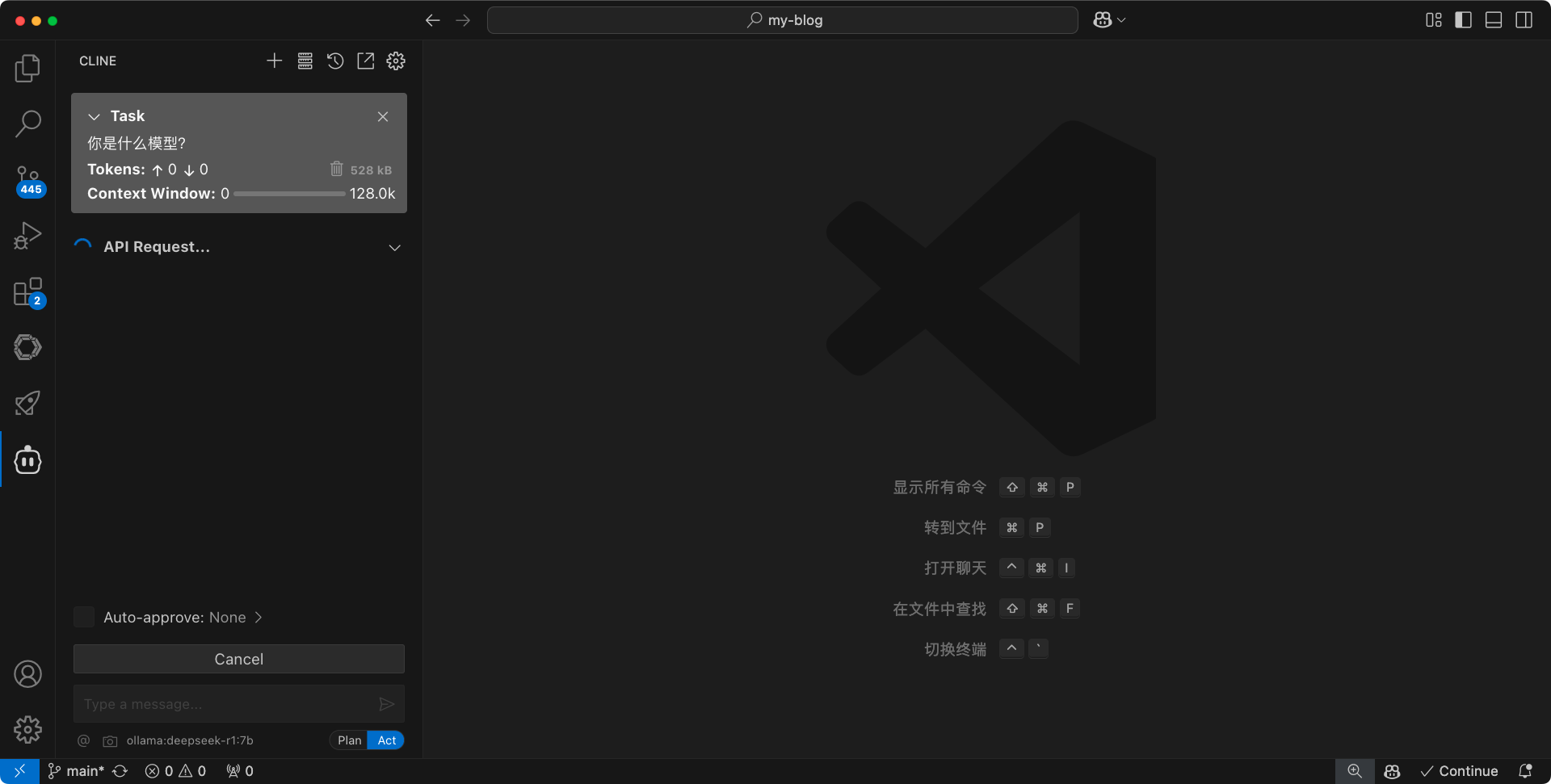
在cline的GitHub项目下面的,issues里面,已经有人反馈了这个问题。目前这个问题,应该还在处理中,具体原因也有待排查。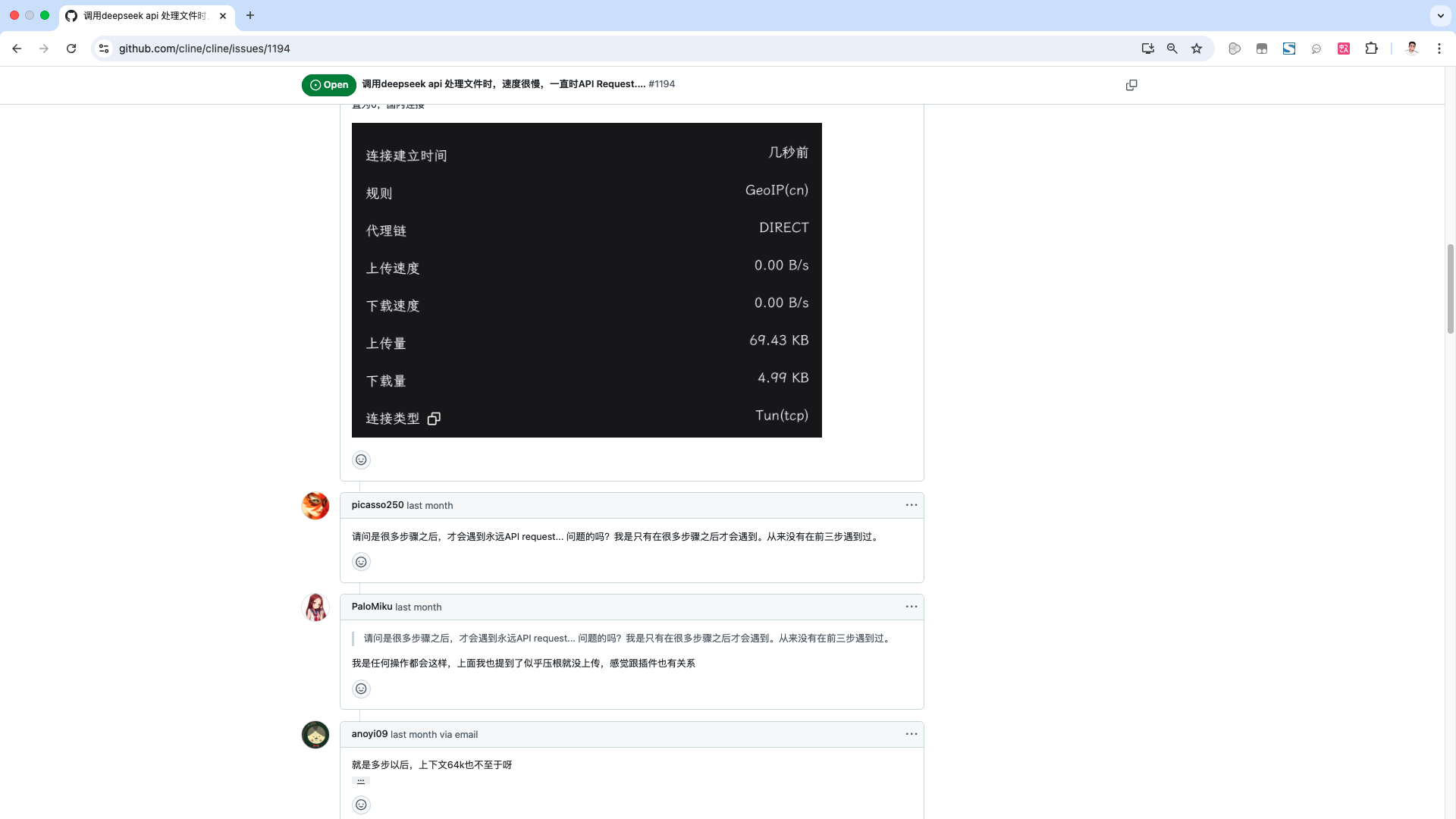
大家在cline或roo code插件中,如果遇到这个问题,可以先使用其它本地模型,或者API的方式。等这个问题修复后,再切换成本地deepseek R1模型。
结束语
deepseek R1 是一个,对标OpenAI o1的国产大模型。它的训练成本远低于同类模型,R1 的出现可能会改变:“要形成AI竞争力,就必须依靠大量的GPU和巨额的训练费用”这一现状。也许在以后,性价比将成为AI发展中的一个重要考虑因素吧。